Java Development Kit (JDK), Java uygulaması geliştirmek, geliştirdiğimiz uygulamaları çalıştırmak ve en nihayetinde uygulamamızın dağıtımını yapmak için çeşitli araçlar (javac, java, javadoc, jar, jlink gibi) sunuyor. Uygulamaların dağıtımını yapmak için jar komutundan ve jar formatından yararlanıyoruz. jar komutu projede yer alan .class uzantılı dosyaları tek bir dosyaya arşivleyip, bu arşiv dosyasını jar uzantılı bir dosyaya sıkıştırıyor. Ağırlıklı olarak Linux sistemlerde yer alan tar ve zip komutunun yaptığı işlemi bize sunuyor. Daha sonra bu jar uzantılı uygulamayı java komutu ile çalıştırıyoruz. jar uzantılı dosyada bir uygulama olabileceği gibi bir çok projede ortak olarak kullanılan bir kütüphane de olabilir.
MODÜL
Yazılım Mimarisi yazılımı parçalara ayırmakla ilgilidir. Yazılımı öyle birimlere ya da parçalara ayıralım ve daha sonra bu birimleri öyle birleştirelim ki işlevsel olmayan özellikleri sağlasın. İşlevsel olmayan özellikler ölçeklenebilirlik, her zaman erişebilirlik, değiştirilebilirlik gibi yazılımın verdiği hizmetin kalitesine yönelik tanımlar içerir. Örneğin İstemci-Sunucu mimarisinde bu parçalar ya da birimler İstemci ve Sunucudur. Örnek olarak MySQL İlişkisel Veritabanını ele alalım. MySQL İstemci-Sunucu mimarisine sahiptir. Sunucu mysqld prosesi olarak bir makinada çalışırken, istemciler ise Java, C/C++, .Net, PHP, Python ya da node.js platformarından birinde yazılmış birer uygulama olabilir. mysqld sunucusu ise Katmanlı Mimariye (=Layered Architecture) sahiptir. Bu katmanlar, mysqld örneğinde aşağıda verildeği şekildedir: i. Bağlantı katmanı, ii. Ayrıştırıcı (=Parser) ve Sorgu Cep Belleği, iii. En İyileyici (=Optimizer) iv. Depolama Motorları (=Storage Engines)
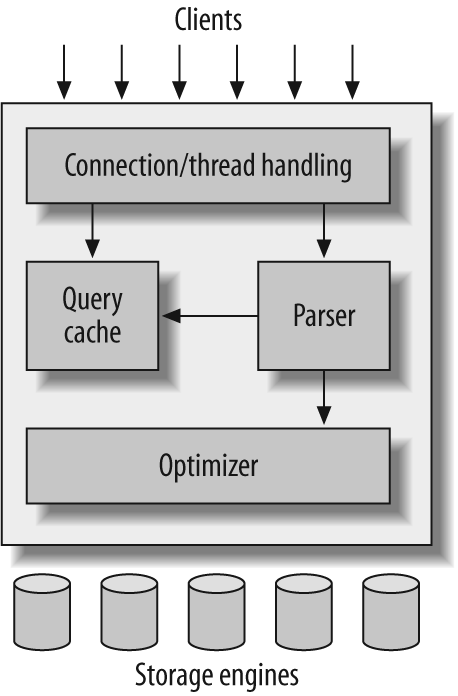 |
| MySQL'in Mimarisi |
Bu katmanların her birini diğerinden ayırt etmek üzere bir birim ya da modül olarak tanımlamak isteriz. Böylelikle uygulamayı geliştirmek, test etmek, değiştirmek, bakımını yapmak daha kolay olacaktır. Bir uygulama Yekpare Mimaride (=Monolithic Architecture) olarak geliştirilmiş olsa bile modüler bir yapıda olmasını yeğleriz. Bu birimleri Windows'ta DLL (Dynamic Link Library) olarak, Linux'da SO (=Shared Object) dosyası olarak ve Java'da ise JAR dosyası olarak tanımlıyoruz.
Java 9 ve MODÜLER PROGRAMLAMA
Java 9'un modüller programlama açısından bakıldığında iki hedefi bulunuyor:
Makinanıza JDK 9+ kurduğunuzda artık içinden rt.jar çıkmadığını göreceksiniz. rt.jar içinde sağlanan işlevler modüller halinde yerinden jmods dizini altında düzenlendiğini görüyoruz:
- İlk hedef JDK'nın modüler bir yapıya kavuşturmak getirmek.
- İkinci hedef JDK üzerinde çalışan onu kullanan uygulamanızın modüler yazılabilmesini sağlamak.
MODÜLER JDK
Java'da Java 9'a kadar modülü ayırt edecek herhangi bir gösterim bulunmuyordu. Jar dosyası kavramsal olarak bir modül içerse bile JVM'nin (Java Virtual Machine) ve Class Loader'ın bunu ayırt etmesini sağlayacak herhangi bir tanımlama jar dosyası içinde yer almaz. Üstelik JVM'nin kendisi modüler değildir: rt.jar ve tools.jar. Platform devasa bu iki jar dosyasından ibarettir ve her yeni sürümde bu jar dosyasının boyutu artmaktadır. Java 9 hem platformun hem de bu platformun üzerinde çalışacak uygulamanın modüler olarak geliştirilmesini sağlayacak yenilikler içeriyor. Bu yazıda bu yenilikler tanıtılmaya çalışılacaktır.Makinanıza JDK 9+ kurduğunuzda artık içinden rt.jar çıkmadığını göreceksiniz. rt.jar içinde sağlanan işlevler modüller halinde yerinden jmods dizini altında düzenlendiğini görüyoruz:
c:\stage\opt\jdk-9.0.4>dir Directory of c:\stage\opt\jdk-9.0.4 01/19/2020 08:01 AM <DIR> . 01/19/2020 08:01 AM <DIR> .. 01/19/2020 08:00 AM <DIR> bin 01/19/2020 08:00 AM <DIR> conf 12/19/2017 06:31 PM 3,244 COPYRIGHT 01/19/2020 08:00 AM <DIR> include 01/19/2020 08:00 AM <DIR> jmods 01/19/2020 08:00 AM <DIR> legal 01/19/2020 08:01 AM <DIR> lib 11/04/2019 12:40 PM 158 README.html 11/04/2019 12:40 PM 1,950 release
jmods dizini içinde 98 adet jmod uzantılı dosya yer alıyor. Bu modüllerin her birinin tek bir sorumluluğu olacak şekilde düzenlendiğini görüyoruz:
c:\stage\opt\jdk-9.0.4\jmods>dir Directory of c:\stage\opt\jdk-9.0.4\jmods 01/19/2020 08:00 AM <DIR> . 01/19/2020 08:00 AM <DIR> .. 11/04/2019 12:40 PM 61,160 java.activation.jmod 11/04/2019 12:40 PM 16,673,580 java.base.jmod 11/04/2019 12:40 PM 111,467 java.compiler.jmod 11/04/2019 12:40 PM 2,689,556 java.corba.jmod 11/04/2019 12:40 PM 51,910 java.datatransfer.jmod 11/04/2019 12:40 PM 13,681,645 java.desktop.jmod 11/04/2019 12:40 PM 127,281 java.instrument.jmod 11/04/2019 12:40 PM 18,864 java.jnlp.jmod 11/04/2019 12:40 PM 120,151 java.logging.jmod 11/04/2019 12:40 PM 880,278 java.management.jmod
.
.
.
11/04/2019 12:40 PM 78,541 jdk.security.auth.jmod 11/04/2019 12:40 PM 24,052 jdk.security.jgss.jmod 11/04/2019 12:40 PM 527,308 jdk.snmp.jmod 11/04/2019 12:40 PM 18,490 jdk.unsupported.jmod 11/04/2019 12:40 PM 1,940,012 jdk.xml.bind.jmod 11/04/2019 12:40 PM 42,434 jdk.xml.dom.jmod 11/04/2019 12:40 PM 741,290 jdk.xml.ws.jmod 11/04/2019 12:40 PM 87,995 jdk.zipfs.jmod 11/04/2019 12:40 PM 2,624 oracle.desktop.jmod 11/04/2019 12:40 PM 8,938 oracle.net.jmod
jmod dosyası aslında bir jar dosyasıdır. İçinde modül bilgisi, modülü oluşturan class dosyaları yer alıyor. Modül bilgisi ve modüller arasındaki bağımlılıklar module-info.class dosyası içinde tanımlıdır. Modül listesini Java Sanal Makinasından list-modules seçeneği ile öğrenebilirsiniz:
c:\stage\opt\jdk-9.0.4>java --list-modules java.activation@9.0.4 java.base@9.0.4 java.compiler@9.0.4 java.corba@9.0.4 java.datatransfer@9.0.4 java.desktop@9.0.4 java.instrument@9.0.4 java.jnlp@9.0.4 java.logging@9.0.4 java.management@9.0.4
.
.
.
jdk.security.auth@9.0.4 jdk.security.jgss@9.0.4 jdk.snmp@9.0.4 jdk.unsupported@9.0.4 jdk.xml.bind@9.0.4 jdk.xml.dom@9.0.4 jdk.xml.ws@9.0.4 jdk.zipfs@9.0.4 oracle.desktop@9.0.4 oracle.net@9.0.4
Modül dosyası oluşturmak, modül dosyası içindeki dosyaları listelemek ve açmak ve modüller arasındaki bağımlılığı listelemek için jmod komutunu kullanabilirsiniz. Aşağıda jmod komutunun kullanımları örneklenmiştir:
c:\stage\opt\jdk-9.0.4>jmod describe jmods\java.sql.jmod java.sql@9.0.4 exports java.sql exports javax.sql exports javax.transaction.xa requires java.base mandated requires java.logging transitive requires java.xml transitive uses java.sql.Driver platform windows-amd64
c:\stage\opt\jdk-9.0.4>jmod list jmods\java.sql.jmod classes/module-info.class classes/java/sql/Array.class classes/java/sql/BatchUpdateException.class classes/java/sql/Blob.class classes/java/sql/CallableStatement.class classes/java/sql/ClientInfoStatus.class classes/java/sql/Clob.class classes/java/sql/Connection.class classes/java/sql/ConnectionBuilder.class classes/java/sql/DatabaseMetaData.class
.
.
.
classes/javax/sql/RowSetReader.class classes/javax/sql/RowSetWriter.class classes/javax/sql/StatementEvent.class classes/javax/sql/StatementEventListener.class classes/javax/sql/XAConnection.class classes/javax/sql/XAConnectionBuilder.class classes/javax/sql/XADataSource.class classes/javax/transaction/xa/XAException.class classes/javax/transaction/xa/XAResource.class classes/javax/transaction/xa/Xid.class legal/COPYRIGHT legal/LICENSE
JDK'nın bu yeni modüler yapısı sayesinde uygulamanıza özel bir JDK oluşturabilirsiniz. Bunun için öncelikle uygulamanızın ihtiyacı olan modüllerin bir listesini çıkarmanız gerekir. Ardından jlink komutu ile sadece tanımladığınız bu listede yer alan modüllerden oluşan bir JDK oluşturabilirsiniz:
c:\stage\opt\jdk-9.0.4>jlink --module-path jmods --add-modules java.sql,java.sql.rowset,java.xml --output c:\tmp\jdk9-app42
Sadece ihtiyacımız olan modüllerden oluşan JDK c:\tmp\jdk9-app42 dizininde oluştu:
c:\tmp\jdk9-app42>dir Directory of c:\tmp\jdk9-app42 04/11/2019 10:49 PM <DIR> . 04/11/2019 10:49 PM <DIR> .. 04/11/2019 10:49 PM <DIR> bin 04/11/2019 10:49 PM <DIR> conf 04/11/2019 10:49 PM <DIR> include 04/11/2019 10:49 PM <DIR> legal 04/11/2019 10:49 PM <DIR> lib 04/11/2019 10:49 PM 121 release
Bu yeni JDK bir taraftan uygulamanızın daha hızlı açılmasını sağlarken diğer taraftan uygulamanızı kullanmadığı modüllerde oluşabilecek güvenlik açıklarından korumanızı sağlayacaktır. Uygulamanızı çalıştırmak için eskiden olduğu gibi java komutunu kullanacaksınız. Ancak bu kez java komutu olarak yeni JDK'daki bin dizininde yer alan java komutunu kullanacaksınız:
c:\tmp\jdk9-app42\bin>java -jar c:\tmp\app42.jar
MODÜLER JAVA UYGULAMASI GELİŞTİRMEK
- Random Module: Sözde rastgele sayı üretmekten sorumlu modül
- Lottery Module: Sayısal Loto için sayı üretmekten sorumlu modül
- Application Module: Uygulama modülü
Random Module
Random modülü sözde rastgele sayı üretmekten sorumlu bir modül olarak tasarlanmıştır. Modülün vereceği bu hizmeti dışarıya bir Java arayüzü (com.example.random.service.RandomService) üzerinden açacağız. Bu arayüzün gerçeklemelerine ait detaylarını (com.example.random.service.business.SimpleRandomService ve com.example.random.service.business.SecureRandomService sınıfları) ise modül içinde gizliyoruz.
module-info.java:
module com.example.random { exports com.example.random.service; provides com.example.random.service.RandomNumberService with com.example.random.service.business.SimpleRandomNumberService, com.example.random.service.business.SecureRandomNumberService; }
QualityLevel.java:
package com.example.random.service; public enum QualityLevel { SECURE, SIMPLE }
Quality.java:
package com.example.random.service; import static java.lang.annotation.ElementType.METHOD; import static java.lang.annotation.ElementType.TYPE; import static java.lang.annotation.RetentionPolicy.RUNTIME; import java.lang.annotation.Documented; import java.lang.annotation.Retention; import java.lang.annotation.Target; @Documented @Retention(RUNTIME) @Target({ TYPE, METHOD }) public @interface Quality { QualityLevel value(); }
SecureRandomNumberService.java:
package com.example.random.service.business; import java.security.SecureRandom; import java.util.Random; import com.example.random.service.Quality; import com.example.random.service.QualityLevel; import com.example.random.service.RandomNumberService; @Quality(QualityLevel.SECURE) public class SecureRandomNumberService implements RandomNumberService { private Random rand = new SecureRandom(); public SecureRandomNumberService() { System.err.println("SecureRandomNumberService is created!"); } @Override public int generate(int min, int max) { System.err.println("SECURE implementation is used!"); return rand.nextInt(max - min) + min; } }
SimpleRandomNumberService.java:
package com.example.random.service.business; import java.util.Random; import java.util.concurrent.ThreadLocalRandom; import com.example.random.service.Quality; import com.example.random.service.QualityLevel; import com.example.random.service.RandomNumberService; @Quality(QualityLevel.SIMPLE) public class SimpleRandomNumberService implements RandomNumberService { private Random rand = ThreadLocalRandom.current(); public SimpleRandomNumberService() { System.err.println("SimpleRandomNumberService is created!"); } @Override public int generate(int min, int max) { System.err.println("CHEAP implementation is used!"); return rand.nextInt(max - min + 1) + min; } }
LotteryService.java:
package com.example.random.service; public interface RandomNumberService { int generate(int min,int max); }
Lottery Module
Lottery modülü Sayısal Loto için 6 tane birbirinden farklı 1 ile 49 arasında sıralı sayı üretmekten sorumlu bir modül olarak tasarlanmıştır. Lottery modülü rastgele sayı üretmekten sorumlu olan Random Modülünü kullanıyor. Bu durumu module-info.java dosyasında requires anahtar kelime ile ifade ediyoruz:
module-info.java:
import com.example.random.service.RandomNumberService; module com.example.lottery { requires com.example.random; exports com.example.lottery.service; uses RandomNumberService; provides com.example.lottery.service.LotteryService with com.example.lottery.service.business.SimpleLotteryService; }
LotteryService.java:
package com.example.lottery.service; import com.example.random.service.RandomNumberService; import java.util.List; public interface LotteryService { List<Integer> draw(); List<List<Integer>> draw(int n); void setRandomNumberService(RandomNumberService randomNumberService); }
SimpleLotteryService.java:
package com.example.lottery.service.business; import java.util.List; import java.util.stream.Collectors; import java.util.stream.IntStream; import com.example.lottery.service.LotteryService; import com.example.random.service.RandomNumberService; public class SimpleLotteryService implements LotteryService { private RandomNumberService randomNumberService; @Override public void setRandomNumberService(RandomNumberService randomNumberService) { this.randomNumberService = randomNumberService; } @Override public List<Integer> draw() { return IntStream.generate(() -> randomNumberService.generate(1, 50)) .distinct() .limit(6) .sorted() .boxed() .collect(Collectors.toList()); } @Override public List<List<Integer>> draw(int n) { return IntStream.range(0, n) .mapToObj(i -> this.draw()) .collect(Collectors.toList()); } }
Application Module
Uygulama modülü hem Lottery modülüne hem de Random Modülüne bağımlılığı bulunuyor. Bu durumu module-info.java dosyasında requires anahtar kelimesi ile tanımlıyoruz. Uygulamamız ayrıca bu modüllerdeki LotteryService ve RandomNumberService arayüzlerini gerçekleyen servis sınıflarını kullanacağını ise uses anahtar kelimesi ile tanımlıyoruz:module-info.java:
import com.example.lottery.service.LotteryService; import com.example.random.service.RandomNumberService; module com.example.lottery.app { requires com.example.lottery; requires com.example.random; uses LotteryService; uses RandomNumberService; }
application.properties:
random.number.service.level=SECURE
LotteryApp.java:
package com.example.app; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.util.List; import java.util.Properties; import java.util.ServiceLoader; import java.util.function.Consumer; import com.example.lottery.service.LotteryService; import com.example.random.service.Quality; import com.example.random.service.QualityLevel; import com.example.random.service.RandomNumberService; public class LotteryApp { public static void main(String[] args) throws FileNotFoundException, IOException { Properties props = new Properties(); props.load(new FileInputStream(new File("src","application.properties"))); QualityLevel level = QualityLevel.valueOf(props.getProperty("random.number.service.level")); LotteryService sls = ServiceLoader.load(LotteryService.class).findFirst().get(); sls.setRandomNumberService(extractService(level)); Consumer<List<Integer>> println = System.err::println; sls.draw(10).forEach(println); } private static RandomNumberService extractService(QualityLevel level) { ServiceLoader<RandomNumberService> loader = ServiceLoader.load(RandomNumberService.class); RandomNumberService randomNumberService = null; for (RandomNumberService rns : loader) { Class<?> clazz = rns.getClass(); if(clazz.isAnnotationPresent(Quality.class)) { Quality quality = clazz.getAnnotation(Quality.class); if (quality.value() == level) { randomNumberService = rns; break; } } } return randomNumberService; } }
Örnek uygulamaya https://github.com/deepcloudlabs/modular-programming-example-java9 adresinden erişebilirsiniz.

